
The average body contains about 37 trillion cells – and we are in the midst of a revolutionary quest to understand what they all do. Unravelling this requires the expertise of scientists from all different backgrounds – computer scientists, biologists, clinicians and mathematicians – as well as new technology and some pretty sophisticated algorithms.
Where once a primitive microscope, essentially little more than a magnifying glass, would reveal a new cell directly and viscerally – in the same way that Antonie van Leeuwenhoek discovered sperm in 1677 – today it is analysis on a computer screen which brings us such revelations. But it’s just as wonderful.
This type of research is hard in all sorts of ways – from the science itself to the sociology of large teams working on it – but the pay-off can be huge. It certainly was for a consortium of 29 scientists who set out to determine which types of cells make up the lining of the trachea, or windpipe – and stumbled upon a new type of cell that could transform our understanding and treatment of cystic fibrosis.
The first time the team – co-led by Aviv Regev at the Broad Institute of MIT and Harvard – came across these cells, they were looking at an analysis of 300 cells in the trachea of mice. Three cells didn’t seem to correspond to anything that had been seen before. Had it been just two, they might have dismissed it as an outcome of noise in the data – but three strange cells warranted a closer look.
In lab banter, they became known as the “hot cells”. The scientists repeated the experiment several times, and it soon became clear they really had stumbled upon a new type of cell in the trachea.

This story is part of Conversation Insights
The Insights team generates long-form journalism and is working with academics from different backgrounds who have been engaged in projects to tackle societal and scientific challenges.
As it turned out, another team from the US and Switzerland had independently found the same thing. The two teams learnt of each other’s work by chance at a seminar in 2017. “It was one of those beautiful moments in science,” recalled Moshe Biton from the Broad Institute team, “when two groups found the same results separately.”
Both groups confirmed that these new cells exist in the human airways as well as in mice and, after meeting up, agreed to publish their two papers side-by-side. These new cells had not been noticed before, simply because they are so rare – they make up around 1% of cells in the airway. But that doesn’t mean they’re unimportant. When the two teams looked in detail at what made these cells stand out, they came across something astonishing.
One of the genes active in these new-found trachea cells turned out to be CFTR – the “cystic fibrosis transmembrane conductance regulator” gene. This gave their work a whole other level of meaning because mutations in this gene cause cystic fibrosis.
Exactly how this disease is caused by the inheritance of a dysfunctional version of the CFTR gene has been a mystery ever since the link was discovered in 1989. Cystic fibrosis is a complex disease, usually beginning in childhood, with symptoms often including lung infections and difficulty breathing. There are treatments but no cure.
Elevate Your Health for Just $29.99/Month
Join the Precision Wellness Subscription at My Healing 365 and get discounted services, priority coaching access, virtual care, and exclusive wellness resources to support your physical, emotional, and hormonal health.
Join for $29.99/MonthNow it seems possible that the key to understanding the cause could lie in working out what these newly discovered cells do, and what happens to these cells if the CFTR gene is defective. The research continues.
But already from this discovery, and other research using similar methods, there is the sense that our understanding of the body’s cells is being transformed by a piercing new combination of biology and computer science. And this is where even more game-changing discoveries are about to be made.
Table of Contents
The diversity of human cells
Every one of the 37 trillion-or-so cells in your body is unique to some extent. Types of cell are determined by the particular proteins they contain – so only a red blood cell has haemoglobin, for example, and a neuron contains different proteins from an immune cell. No two cells in the body contain exactly the same amounts of each protein.
The immune system is especially complex. It comprises many types of cells categorised by their core function – T cells, B cells and so on. But there are also countless subtle variations of these T cells and B cells. We don’t even really know how many variants there are – but if we could understand what they all do, we would better understand the immune system. This in turn would enable us to design new medicines to help the immune system to, for example, better fight cancer.
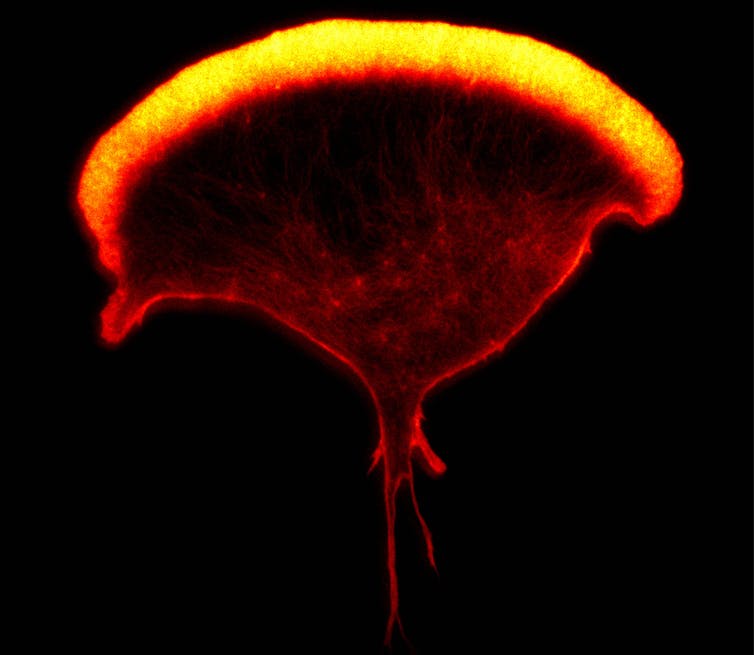
Ashley Ambrose and Daniel M Davis, Author provided
One kind of immune cell that my research team at Manchester University studies is called the natural killer cell. There are about a thousand of these immune cells in each drop of your blood, and they are especially good at detecting and killing other cells that have turned cancerous or have become infected with a virus. Again, not all natural killer cells are alike. One analysis has estimated that there are many thousands of variants of this immune cell in any one person.
In 2020, my research lab carried out an analysis which suggested that variants of natural killer cells in blood could be organised into eight categories. While their different roles in the body aren’t yet fully understood, it’s likely that some are especially adept at attacking particular kinds of virus, others are better at detecting cancer, and so on.
Other types of immune cell can be even more varied. Evidently, our component cells are as diverse as the human beings they make up, and understanding how such complex populations of cells work together (in this case, to defend against disease) is a vital frontier.
Using the language of algorithms
To penetrate this complexity, the diversity of human cells must be translated into the language of algorithms.
Imagine a cell contains just two kinds of protein, X and Y. Every individual cell will have a specific amount of each of these two proteins. This can be represented as a point on a graph where the level of protein X becomes a position along the x-axis, and the level of protein Y its location along the y-axis.
One cell may contain a high amount of protein X and a little of protein Y (which can be revealed by a flow cytometer showing that the cell stains with a high amount of one antibody and a low amount of another antibody). This cell can then be represented as a point placed far along the x-axis and a little way up the y-axis.
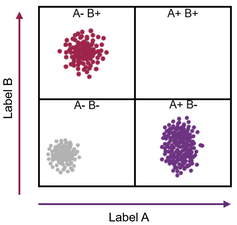
Manon Chauvin via Wikimedia, modified, Author provided
As each cell takes up a position on the graph, those with similar levels of the X and also the Y protein – likely to be the same type of cell – appear as a cluster of points. If thousands or millions of cells are plotted in this way, the number of discrete clusters that emerge tells us how many types of cells there are. Also, the number of points within a cluster tells us how many cells there are of that type.
The wonderful thing is that this form of analysis can reveal how many kinds of cells are present in, say, a sample of blood or a tumour biopsy, without being guided in any way about which cells we are expecting to find. This means that unexpected results can turn up. A cluster of data points might appear with unexpected properties – implicating the discovery a new kind of cell.
Of course, cells need more than two coordinates to describe them. In fact, over the last decade, a type of analysis – known as single-cell sequencing– has been developed to measure the extent to which individual cells use each of the 20,000 human genes it contains.
Which ones out of all the 20,000 human genes a particular cell is using – called the cell’s transcriptome – can then be analysed to create a “map” of different cells. We can’t imagine cells represented on a graph with 20,000 axes, but a computer algorithm can handle this analysis in just the same way it would one with only two variables. Similar cells are positioned close together, while cells using very different sets of genes are far apart.
Algorithms to do this are borrowed from other fields of science, such as those used in analysing social networks. Then we get to spend days, if not years, mining the output, deciphering what the map means: how many types of cells there are, what defines their differences, and what they do in the body?
Right now, this endeavour is happening on an unprecedented scale thanks to the Human Cell Atlas consortium – leading to all kinds of discoveries about the human body.
The Human Cell Atlas
In October 2016, Regev and Sarah Teichmann from the Wellcome Sanger Institute organised an event in London for around 100 world-leading scientists to discuss how to chart every cell in the human body. The elevator pitch was to assemble something like Google Maps for the body: “We know the countries and main cities, now we need to map the streets and buildings.”
A year later, they had drafted a specific plan – to first try to profile 100 million cells from different systems and organs, using different people around the globe. Thousands of scientists in over 70 countries from every inhabited content have joined the consortiu since – it is an especially diverse community, as it should be for such a huge global scientific endeavour.

Thomas Farnetti/Wellcome, CC BY-ND
In many ways, this bold new ambition is a direct descendant of the Human Genome Project. By sequencing all the human genes contained in each human cell, officially completed in April 2003, all sorts of genetic variations have been linked to increased susceptibility to a specific illness.
However, genetic diseases manifest in the specific cells where that gene is normally used. So, crucially, an analysis of genes alone isn’t enough – we also need to know where in the human body these disease-causing genes are being switched on.
The Human Cell Atlas is bridging this gap between abstract genetic codes and the physicality of the human body. We’ve already seen one example of how important this is – the discovery of the cystic fibrosis gene being used by a new, rare cell. Another example comes from what happens during pregnancy.
Unlocking the secrets of pregnancy
For many years, we have known that the immune system is intimately linked with pregnancy. For example, some combinations of immune system genes are slightly more frequent than would be expected by chance in couples who have had three or more miscarriages. While we don’t yet understand why this is, working it out might be medically important in resolving problems in pregnancy.
To tackle the issue, a consortium of scientists (co-led by Teichmann as part of the Human Cell Atlas project) analysed around 70,000 cells from the placenta and lining of the womb from women who had terminated their pregnancy at between six and 14 weeks.
The placenta is the organ where nutrients and gases pass back and forth between the mother and developing baby. It was once thought the mother’s immune system must be switched off in the lining of the womb where the placenta embeds, so that the placenta and foetus aren’t attacked for being “alien” (like an unmatched transplant) on account of half the foetus’s genes coming from the father. But this view turned out to be wrong – or too simple at the very least.
We now know, from a variety of experiments including this analysis, that in the womb, the activity of the mother’s immune cells is somewhat lessened, presumably to prevent an adverse reaction against cells from the foetus, but the immune system is not switched off. Instead, the immune cells we met earlier, natural killer cells, well known for killing infected cells or cancer cells, take on a completely different, more constructive job in the womb; helping build the placenta.
The scientists’ analysis of 70,000 cells has also highlighted that all sorts of other immune cells are also important in the construction of a placenta. What they all do, though, isn’t yet clear – this is at the edge of our knowledge.

Thomas Farnetti/Wellcome, CC BY-ND
Muzlifah “Muzz” Haniffa is one of the three women who led this analysis. As a physician and scientist, she sees the body from two perspectives on an almost daily basis: as a computational analysis of cells on a screen, and as patients who walk through the door. Both as stones and the arch they make.
Right now, these two views don’t easily mesh. But in time, they will. In the future, Haniffa thinks the tools doctors use on a daily basis – such as a stethoscope to listen to a person’s lungs, or a simple blood count – will be replaced by instruments that profile our body’s cells. Algorithms will analyse the results, clarify the underlying problem, and predict the best treatment. Many other physicians agree with her – this is the coming future of healthcare.
What this could mean for you
Babies are now routinely born by IVF, organ transplants have become common, and overall cancer survival rates in the UK have roughly doubled in recent years – but all these achievements are nothing to what’s coming.
As I’ve written about in The Secret Body, progress in human biology is accelerating at an unprecedented rate – not only through the Human Cell Atlas but in many other areas too. Analysis of our genes presents a new understanding of how we differ; the actions of brain cells give clues to how our minds work; new structures found inside our cells lead to new ideas for medicine; proteins and other molecules found to be circulating in our blood change our view of mental health.
Of course, all science has an ever-increasing impact on our lives, but nothing affects us as deeply or directly as new revelations about the human body. On the horizon now, from all this research, are entirely new ways of defining, screening and manipulating health.
We are already accustomed to the idea that our personal genetic information can be used to guide our health. But a quieter – almost secret – revolution is also under way and it may have an even bigger impact on the future of healthcare: deep analytics of the human body’s cells.

Shutterstock
One day, a watch that can measure a few simple things about your body will be seen as a laughably primitive tool. In the future, maybe within ten years or so, a whole cloud of information will be available – including an analysis of your body’s cells – and you will have to decide how much you want to delve into it. This revolution in human biology will equip us individually with new powers – and we will each need to decide for ourselves if and when to deploy them.
You may, for example, one day visit your doctor with something abnormal on your skin – a rash, itch, or something else. The doctor may then take a small sample of your skin, or perhaps a blood sample, and from a complete cell-by-cell analysis of what’s there, be able to precisely diagnose the problem and know the best treatment. Indeed, some of this might even be automated. Further into the future, if the equipment needed to do this gets small and cheap enough, perhaps the analysis could be done by yourself at home.
Diseases will also be more frequently predicted before any symptoms are present at all. Of course, this is one of the most vital missions of science: to stop human disease before it even begins. For some illnesses, this has been achieved already – with vaccines, clean water and improved sanitation. Now, with the human body opening up to us through computational analysis of cells, genes and more, new ways of pre-empting disease are emerging. We are compelled to seize this new opportunity – yet in practice, there are challenges and unintended consequences to contend with.
Take a familiar example: the idea of the body-mass index, a value derived from a person’s weight and height. This is used to label us as underweight, normal weight, overweight or obese. It’s useful as it indicates an increased risk of health problems arising, such as type 2 diabetes, and steps can be taken to reduce the likelihood of this occurring. But the label itself can also trigger other sorts of problems relating to a person’s self-worth, and how society views obesity and human diversity.
Difficult decisions about how you live
Every one of us is susceptible to some disease or other, to some extent. So as science progresses and we learn more and more about ourselves, we will surely all find ourselves drowning in data about ourselves, awash with estimates and probabilities that play games with our mind and our identity, and require us to make difficult decisions about our health and how we live.
It seems feasible, for example, that the state of a person’s immune system, analysed in depth, could help predict the symptoms they are likely to have if infected with the Sars-CoV-2 virus, for example. Markers of immune activity might even correlate with a person’s mental health. One analysis concluded that particular pro-inflammatory secretions from immune cells (called cytokines) are found at higher levels in people who are depressed.
Read more:
Coronavirus: we must step up research to harness immense power of the immune system
As we learn about the composition and status of the human body, this will inevitably establish new ways of assessing health. And it may very well help resolve problems in pregnancy too, as we’ve seen. But there are problems here too – if an analysis suggests a chance of a problem, say 50%, how would you act on this information if the medical intervention that could help has its own risks too?
There is seemingly no end to how the metric analysis of the human body will lead to important but complex new health decisions. Angelina Jolie famously acted on genetic information when she had both of her breasts surgically removed in 2013, and later her ovaries and fallopian tubes, following a genetic test which established that she had inherited a particular variation in a gene known as BRCA1. Crucially, she had been given a very high – 87% – chance of developing breast cancer. In general, risks and probabilities about our health are much less clear than this.
So the question arises, how are we to act on all this new information? What if something has been identified that means your risk of developing an autoimmune disease or cancer is one in six in the next ten years? Would it be different if it was one in four? At what point would you decide to take medicine as a precaution, or undergo surgery, knowing that they also carry their own risks? And would this knowledge in itself make you feel ill? Would your identity be affected?
I don’t have the answers – but that’s the point. As this new science progresses, each of us will have to decide how much we really want to know about ourselves.

For you: more from our Insights series:
To hear about new Insights articles, join the hundreds of thousands of people who value The Conversation’s evidence-based news. Subscribe to our newsletter.
![]()
This article is an edited extract from Daniel M. Davis' new book The Secret Body (Vintage paperback, 2022). Davis is also the author of two previous books The Beautiful Cure and The Compatibility Gene. He receives research funding from The Medical Research Council, Cancer Research UK, Wellcome, GSK and Bristol Myers Squibb. He tweets at @dandavis101























{kind=link}